
Basic environments
For years I’ve heard everywhere that immutable microservices are the best and while the developer community embraces this technique with read-only Docker images and CI/CD’s, the Operations world seem to be stuck in manual labour changes. Reasons? We just didn’t have the tools to do it. We could deploy some stuff immutable but the lack of internal API’s, software and knowledge kept us stuck in the hope that the previous Operations colleague wrote some documentation that was both readable and complete. On top of that, we just had to cross our fingers that the situation had not changed since the documentation was written.
But, especially in the Cloud environment, with the rise of API’s and IaC tooling, we can hopefully put these dark ages behind us.
If everything has been defined through IaC and some strange error occurs that is out of our hands, we can just destroy that resource and deploy it again. No need to waste time on fixing an unfixable error. Any debugging of the problem can be done afterwards but at that point your business just wants a working application.
Probably the number one selling point of a cloud provider. In the unlikely event that a disaster strikes a cloud-region, you can easily move to another region. This is only true if you have defined everything as IaC. If you start utilizing manual changes with IaC and some other tools you will get stuck in a panic situation. So, try to define everything in your IaC or be prepared to increase your RTO.
In the past, changes were permanent in the Operations world. Some changes could not even be rolled back. With IaC we can rollback or at least redeploy to a previous state. Some IaC do not allow rollbacks (Terraform) and utilize a “move-ahead” strategy. Both have their benefits and disadvantages but I personally think it is mostly a preference of the team what to use.
When you deploy something in the Operations world, your co-workers just hope that you did it correctly. They aren’t going to sit next to you to check your work. They aren’t going to re-check everything afterwards, they (and you) just hope that you did it correctly. With IaC we can finally adopt a version-control workflow. Co-workers can check what you are going to deploy and give you the okay. They can read exactly what is going to deploy and comment or change things with you. Forgot to enable encryption? Easily detected now without a yearly audit of all resources.
Especially in Operations teams this was a problem. You were dropped with a bunch of co-workers and all of them did their own thing. Checks and balances did not really exist and your team-lead was probably hoping everything was going smoothly. And for the most part, it was.
But it did hinder new hires, as every co-worker had his own way of deploying things, every co-worker had his own ritual to pray and bring offers to the Operations-gods.
With IaC bad habits can be addressed, sharing of knowledge and code can be done much faster, the minimum requirements can be enforced,…
A bit in line with the previous point but we can finally make it easy for fellow co-workers to implement necessary parts of a deployment. Organization wide we can easily create modules of infrastructure, others can build further upon them or change them with best practices for the whole organization. Operations can utilize Open-Source modules that are freely shared on the internet.
I remember the first time I needed to deploy an EKS on AWS and was so happy for the EKS module on the Terraform registry. A weeks worth of work suddenly became a day’s work.
Drifts are a pain in the ass. Drifts happen when business requests for something to happen very fast. A fast change to the infrastructure, never documented anywhere and the person that executed the request is on vacation. Suddenly everything is crashing and nobody understands why. Resetting doesn’t work either. Pure chaos and where the hell did that Redis instance suddenly come from?
Yes, your environment has drifted from the initial architecture and because of bad documentation, ignored procedures,… the drift was undetected for years until it all came crashing down.
That is where IaC excels in and shows a very big benefit in my eyes. Your environment can become something that is “immutable”. With tools we can detect resources that are created outside IaC tooling. Changes to resources without the IaC tooling will be detected by the tooling itself.
It can make your whole account like a docker image that you can redeploy when it isn’t working like it is supposed to.
When your environment is defined as IaC it is super-easy to create sandbox environments. Want to test some things that require infrastructure changes? Spin up a sandbox-account and deploy your whole infrastructure in it. After your tests? Destroy it.
If you have a dev-environment, it can also be the perfect place to test if your IaC code is still okay by nuking the whole dev-environment and letting your pipeline rerun. Best case? Your dev environment is back on-line in an hour. Worst case? You have some new action points to address.
Here I’ll try to explain the general guidelines for making sure that at least your production environment is immutable in an infrastructure view.
I do hope you are using some sorts of environment strategy and are not the joke of “your test environment is our production environment”. For small companies this should be a test -> production where both are siloed from each other. Bigger companies can afford a test -> staging -> production strategy. For now, I’ll take the example of a big company to showcase the differences. But as always, this is not a set in stone framework.
This is… the sandbox. Your workload is deployed here but your DevOps team also has Administrator rights in this environment (with maybe some exclusions and small restrictions but for the most part, they are gods here). Here they can experiment, try out different things, change the application how they want it. Your pipeline will still run here to reset the environment to a previous state but it won’t destroy resources created outside of IaC.
The test environment can also be the environment to test your disaster recovery capabilities. Something that maybe occurred once a year can now be done even weekly by just nuking the whole environment and letting the pipeline run. This also resets the sandbox to the stable state after your developers played in it.
Ok, the try-out before production. This is a clone of your production environment with maybe some exceptions like only 2 instances are running instead of 50 (a bit of cost optimizations). This is an environment that you could also call a pilot-light environment. At any time you should be able to scale this environment to run production workloads. Your DevOps team does have Read-only permissions in this environment so they can check the logs, see if any problems arise, debug a bit and so on. But changes to the infrastructure must happen through IaC. Deployments to this environment also need to have approval of the DevOps team.
The real deal. Real customers end up here and that is why… it is a black box for developers except with day-permissions and some general dashboards. Maybe this is a left-over from my time in the finance/medical sector but even logging here can contain personal information which your DevOps team isn’t authorized to just willy-nilly see. A dashboard showing the health of the environment is okay and if customers complain, access can still be granted for a DevOps to check it out. But for the rest? Locked down.
This environment is as staging is, purely read-only. The only changes that should happen here are through IaC with management approval.
In the event of an emergency a break-glass procedure you can give a DevOps additional power to even make changes.

So, we have our environments. Let us now deploy to them. For this you can use any given CI/CD tool. Github, Bitbucket, AWS Codepipeline,… most of them have the basic authorization and tools that we need.
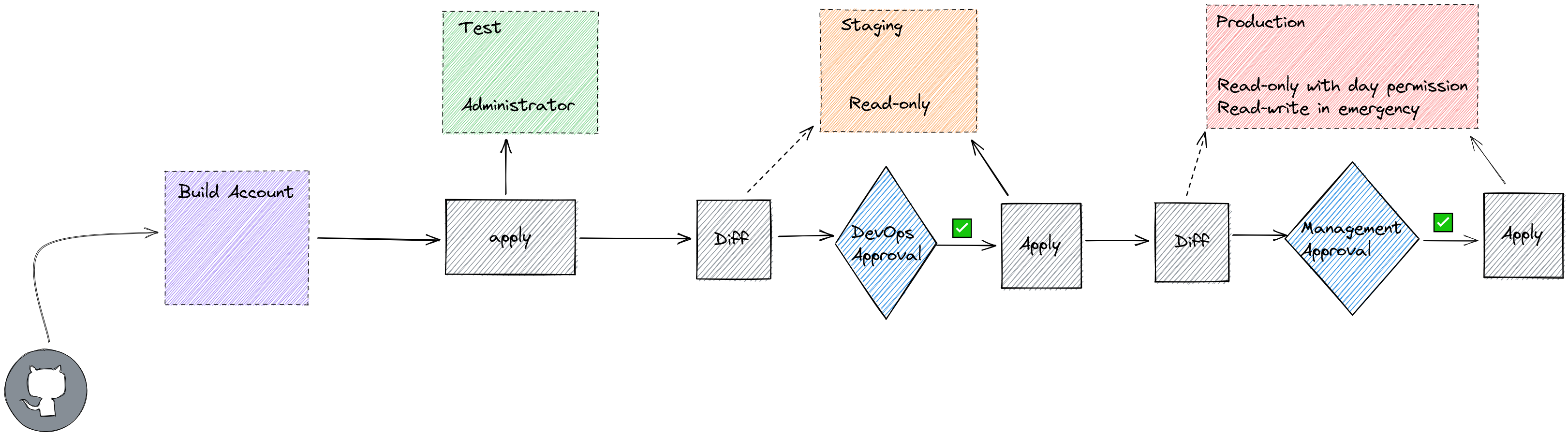
The build account is the account with permissions to all other accounts. You can have a build account per workflow, department, organization,… Just make sure this is a very secure account as the pipeline will mostly have administrator access to all other accounts!
The build account will contain images of operating systems, services,… which other accounts can talk to and utilize.
This is the stage where we can see what is going to happen.
CloudFormation calls this ChangeSets, Terraform has the
plan command, CDK has diff. Nothing actually
happens in this stage except for the IaC tooling checking what is the
current state and what is going to change. IaC tooling like Terraform
will check if the state is still correct with the actual situation by
calling API’s, CloudFormation takes a bit of a dumber approach by just
checking against the state file in the background.
As you may have noticed, we don’t require any approval to deploy to DEV. Some teams do implement it but some don’t. This is something that should be discussed with the team.
To deploy to staging you should request that another DevOps checks what the changes are going to be, staging maybe isn’t production but it is the environment testers are working on, the environment that mimics production,… So any big disruptions still need to have some sort of communication.
When deploying to production it is best to also let management give approval. This is to ensure that management is also up to speed with the changes that are going to happen and they can communicate this to other departments or look at the best time window to execute these changes.
This is the stage that the magic happens, actual changes to the infrastructure will happen here. This is also where staging becomes very important as I’ve noticed over the years that the plan, change set, diff,… sometimes forget something. This part is not theoretical but practical. It is also very handy to see how long any disruption would be, how long it takes to apply all changes,… vital information before you go to production.
At the production apply stage, you pray to the Operations God and have a bottle of whiskey close by.
The shorter the better. Just make sure to do some (automated) tests before deploying further. The difference between Development and Staging can be much bigger than the differences between Staging and Production. Try to keep those two very tight. When a change to Staging happens and it is okayed you should deploy it to Production before any other changes happen to Staging.
Why? Imagine you are setting up a database, some front-end servers, some caching serves,… You deploy this to Staging as first the databases, a day passes, than the caching servers, another day passes, then the front-end servers. Everything is working fine and dandy so you push forward to production and it all comes crashing down.
You investigate and what do you see? The front-end servers were first to deploy, they tried to connect to the databases and cache servers but they didn’t exist yet so they started to terminate themselves. Because they were crashing the IaC tooling stopped as it was receiving errors and neither your database nor caching server have even been deployed yet.
So keep Staging as close to Production as possible.
Ok, we have an environment but… we need to be sure that it is immutable.
The first part of making it immutable is to check if any drifts occurred with resources deployed by IaC. We can check this very fast with the built in commands in the IaC tooling. With Terraform we can create a nightly plan. If the plan detects any drifts we should raise an alarm or move to apply. Depends on what your team prefers. Let me just say, I’ve only seen the alarm being implemented and never the apply 😅.
For the CDK/Cloudformation you can check for any drifts by running the drift command. Do note… this doesn’t work for every resource which is a huge pain in the ass.
The first part was very easy, IaC checks if resources have been modified outside their control. But what they can’t do is… check if resources have been created without any action from their part. A hacker could deploy 20 crypto mining instances and IaC tools would say “nothing wrong on our part” (And yes, they are right, that isn’t their responsibility). Here we could start using a range of tools, some of which are native to the cloud provider themselves (check for tags for example -> an awake hacker will probably notice this), some are third-party like driftctl.
This is something you start from a security account. You can also decide that on production a script would insta-terminate these resources like with aws-nuke. This is making it very close to an immutable environment, killing what is not defined by IaC.
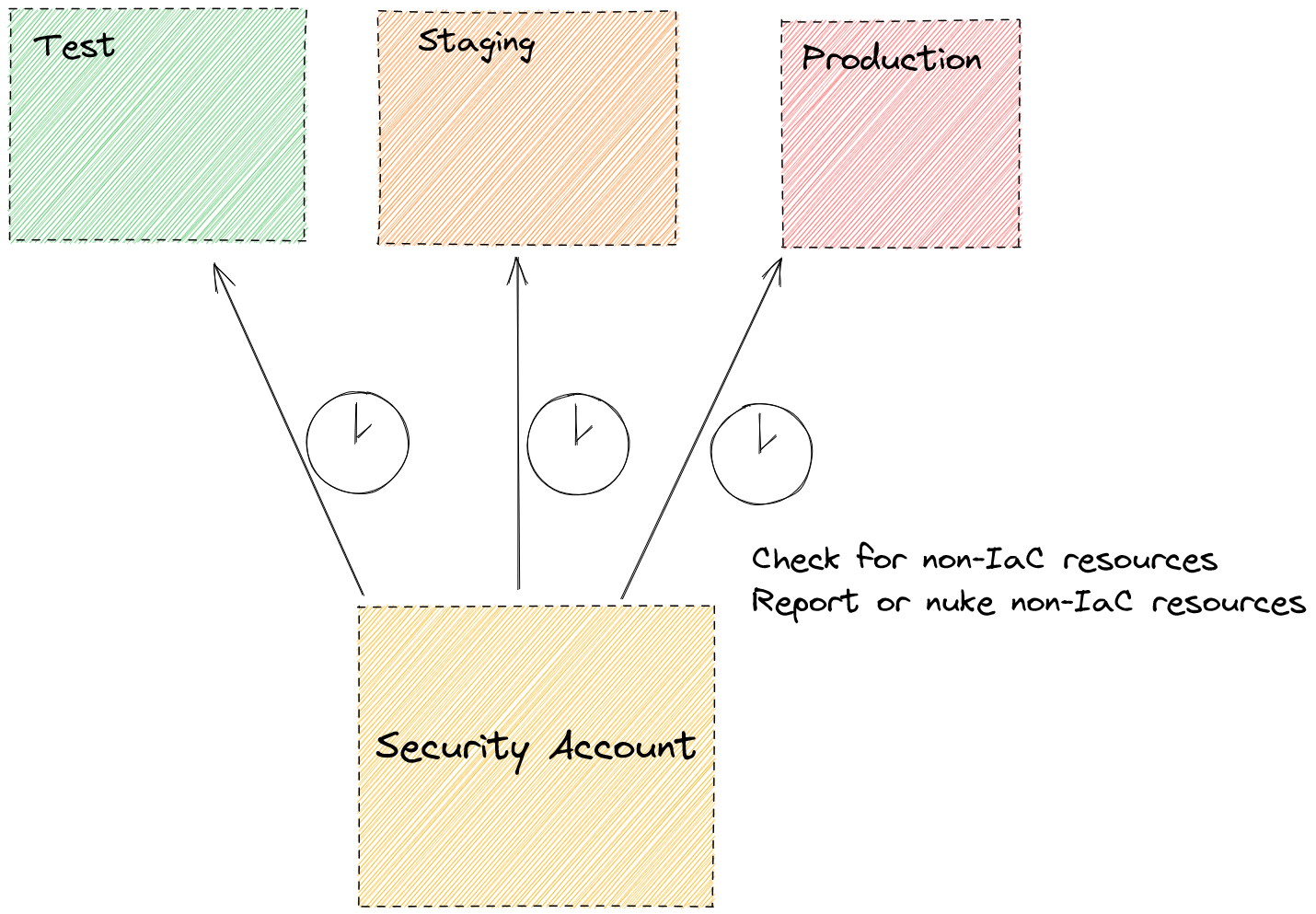
Another way to check if any resources are created outside IaC code is
by looking for example at AWS CloudTrail and filter on
write-actions. Did these write-actions happen outside the pipeline role?
Send an alarm! This isn’t 100% failure proof as a hacker could have
attacked your environment by using the pipeline role!
As with many things, it is a combination of tools and practices. I do
hope I gave you some ideas for your environments and you can always mail
me at [email protected].